【一覧付】システム運用設計の基本項目と作り方|稼働直後のパニックを防ぐ現場の知恵


「いよいよ来週リリースだけど、障害が起きたときの連絡先って誰だっけ・・・・・・」
「ユーザーからの操作問い合わせが、開発メンバーに直接飛んできて作業が止まる・・・・・・」
「本番環境のログ、誰がいつ確認するルールになっているの?」
システム開発のプロジェクトにおいて、最大の山場はリリースだと思われがちです。しかし、現場を預かるPMやリーダーにとって、本当の戦いは稼働した瞬間から始まります。
せっかく苦労して作ったシステムも、運用設計がガタガタでは、リリース直後に現場は混乱し、ユーザーの信頼を一気に失墜します。最悪の場合、開発メンバーが不具合対応と問い合わせ対応に追われ、次プロジェクトの開始が立ち行かなくなることも少なくありません。
今回は、そんな稼働後の地獄を避け、システムを無事に着地させるための「システム運用設計」について、現場目線で具体的に解説します。
運用ルールを軽視したプロジェクトに待ち受ける「稼働直後の地獄」
もし運用設計を行わないまま本番稼働を迎えたらどうなるでしょうか。現場でよく起こる事象をまとめました。
| 発生する問題 | 具体的な事象とリスク |
|---|---|
| 「誰がボールを持つか」の押し付け合い | 障害発生時、インフラ担当かアプリ担当か、あるいは保守ベンダーか、責任の所在が曖昧で初動が遅れます。 |
| 開発メンバーの疲弊 | 適切な窓口(ヘルプデスク等)がないため、ユーザーからの「使い方がわからない」という電話が開発者のデスクに直接かかってきます。 |
| 二次災害の発生 | 承認フローを通さず、良かれと思って現場判断でデータを直接修正し、システム全体の不整合が拡大します。 |
これらはすべて、運用設計(=作った後のルール)を事前に合意できていないことが原因です。
【一覧表】システム運用設計で決めるべき基本項目
まずは、運用設計で何を決めなければならないのか、全体像を把握しましょう。大きく分けて稼働直後の初期流動フェーズと安定稼働後の中長期フェーズで必要な項目が変わります。
| フェーズ | 運用設計の必須項目 | 目的・決めること |
|---|---|---|
| 初稼働直後 (初期流動) | 1. インシデント管理とFAQ | 問い合わせの受付窓口、起票ルール、ナレッジの蓄積方法 |
| 2. 緊急連絡体制 | 障害発生時のエスカレーションルート(誰にどう連絡するか) | |
| 3. 暫定運用フロー | バグ修正までの間、業務を止めないための回避策(ワークアラウンド)の運用ルール | |
| 安定稼働後 (中長期) | 4. 定期運用と監視ルール | 死活監視、リソース監視、バッチ処理の確認、バックアップ検証 |
| 5. ライフサイクル管理 | OSやミドルウェアのパッチ適用サイクルと検証ルール | |
| 6. 変更管理 | 本番環境への改修(プログラム反映)の承認プロセス |
それでは、各項目の具体的なポイントを見ていきます。
【初稼働直後:安定稼働まで】現場の混乱を鎮める3つの備え
リリースから1〜2ヶ月の初期流動期間は、最もトラブルが起きやすい時期です。この期間を乗り切るために、以下の3つを設計しておきましょう。
1. インシデント管理とFAQ(問い合わせ対応)
ユーザーからの問い合わせを「誰が受け、どう記録し、誰が解決するか」のフローを確立します。
- 管理票の統一
発生日時、事象、優先度、ステータスを一覧化します。管理票に盛り込むべき必須項目は以下の通りです。- 基本情報:受付番号、発生日時、報告者、対象機能
- 状況把握:事象詳細(エラーメッセージ等)、再現性の有無、影響範囲
- 対応管理:優先度(高・中・低)、担当者、現在のステータス(未着手・調査中・保留・完了)
- ナレッジ:原因区分(バグ・操作ミス・仕様・インフラ等)、最終回答内容、完了日
- FAQの先行作成と置き場所
テスト期間中に挙がった質問をまとめておきますが、大切なのはその形と置き場所です。- 検索重視(デジタル):日本のIT現場でシェアの高いNotionやBacklog(Wiki機能)などをおすすめします。全文検索が強力で、更新履歴も残るため、キーワードですぐに最新の答えが見つかる状態を作れます。
- 緊急時重視(紙):ネットワーク障害など、PCが使えない事態に備え、緊急連絡先と初期対応FAQだけは紙で印刷し、現場に備え付けておくのが現場の知恵です。
2. 緊急連絡体制(エスカレーションルール)
特に夜間や休日を含む、緊急時の連絡ルートを定義します。「誰にどの順番で連絡するか」を明確にした連絡網(エスカレーションパス)を作成します。
【サンプル】緊急連絡エスカレーションフロー
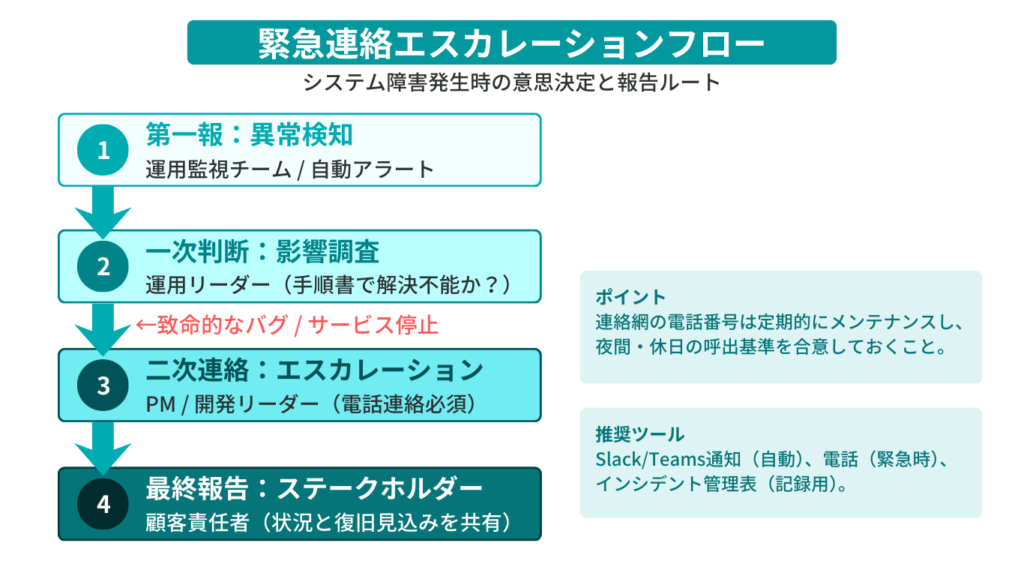
| ステップ | 担当・役割 | アクション内容 | 推奨ツール |
|---|---|---|---|
| ① 第一報 | 運用監視チーム / 自動アラート | 異常の検知と一次切り分け | Slack/Teams自動通知 |
| ② 一次判断 | 運用リーダー | 影響調査。手順書で解決不能なら次へエスカレーション | インシデント管理表 |
| ③ 二次連絡 | PM / 開発リーダー | (致命的なバグやサービス停止の場合)即時連絡 | 電話(緊急時必須) |
| ④ 最終報告 | 顧客責任者 | 状況と復旧見込みの報告と意思決定 | メール / 電話 |
- ポイント:連絡網の電話番号は定期的にメンテナンスし、夜間・休日の呼出基準(どのレベルの障害なら夜中に叩き起こすべきか)をステークホルダーと事前に合意しておくことが重要です。
3. 暫定運用フロー(ワークアラウンド)
バグが見つかっても、すぐにプログラム修正ができるとは限りません。本番環境のプログラムを修正するには、ソースコードの修正だけでなく、再テストや本番反映(デプロイ)の承認フローなど、多くの手順と時間を要するからです。
- 直すか、しのぐかの判断基準
プログラム修正を急ぐあまり、不十分なテストで二次被害を出すのは最悪のシナリオです。まずは手動操作やマニュアル対応でしのげるかを検討します。 - 回避策(ワークアラウンド)の提示
「このボタンは使わず、CSVアップロードで代用してください」「○○画面が使えない間は、管理者が直接DBを更新して対応します」といった暫定的な手順を準備します。 - 承認と周知のフロー
暫定対応を誰の承認で開始し、どうユーザーへ通知するかをあらかじめ決めておきます。これにより、現場が独断で動くリスクを最小限に抑えられます。
【安定稼働後:中長期】システムを「負の資産」にしないための継続ルール
システムが落ち着いてからも、適当な運用を続けていれば、いつか技術的負債として爆発します。
定期運用と監視ルール
「システムが止まることなく、正常に動き続ける状態」を維持するためのルールです。
- 死活・リソース監視
サーバーが動いているか(死活)、CPUやディスク容量に余裕があるかを監視し、閾値を超えた際の通知先を定めます。 - ジョブ・バッチ監視
夜間バッチやデータ連携などの自動処理が正常に終わったかを毎日確認します。ここが漏れると、翌朝の業務開始時にパニックになります。 - バックアップとリカバリ確認
バックアップが取れていることを誰がいつ確認するか、また、実際にそのデータから復旧できるかを定期的に検証します。 - 担当の明確化
「監視システムがアラートを出した後、誰が最初の一歩を踏み出すか」という主担当(一次対応者)を明記することが、放置を防ぐ最大のコツです。
ライフサイクル管理(パッチ適用)
OSやミドルウェアの脆弱性対応は、今や避けては通れない運用タスクです。
- パッチ適用のサイクル化
「緊急時は即時、通常は四半期に一度」など、パッチ適用の頻度と判断基準を明確にします。 - 検証環境での評価
本番に当てる前に、必ず検証環境でパッチを適用し、既存機能に影響(デグレード)が出ないかを確認する手順を必須とします。
保守改修の承認プロセス(変更管理)
本番環境への変更は、常にリスクを伴います。小さな文言修正であっても、「いつ、誰が、何のために、どのテストを経て」本番反映するかを記録し、責任者の承認を得るフローを設計します。
【サンプル】変更管理フローのステップ
| 手順 | 役割 | 実施内容 |
|---|---|---|
| 1. 変更申請 | 開発担当者 | 変更内容・影響範囲・テスト結果を起票する。 |
| 2. 技術審査 | 開発リーダー | コード品質とテストの網羅性をチェックする。 |
| 3. リリース承認 | 運用責任者 / PM | 本番反映のタイミングとリスクを最終判断する。 |
| 4. 本番反映 | 運用・インフラ担当 | 承認された資材のみを、本番環境へデプロイする。 |
| 5. 完了確認 | 開発・運用担当 | 反映直後の正常動作を確認し、申請票をクローズする。 |
運用設計はいつから着手する?運用部門を巻き込むベストなタイミング
運用設計において最もやってはいけないのが、開発チームだけでルールを決めて運用チームに押し付けることです。これをやると、本番稼働後に「そんなの聞いていない」「今の体制では対応できない」といった拒絶反応が起こり、運用が破綻します。
運用部門を巻き込むメリット
- 実現性の担保
「24時間365日の監視」と言っても、運用チームの交代制シフトがどうなっているかを知らなければ、現実的なエスカレーションは組めません。 - 既存標準の活用
多くの会社にはすでに全社共通の運用ルールが存在します。これに合わせることで、運用のコストを下げられます。 - 当事者意識の醸成
設計段階から意見を取り入れることで、運用チーム側に「自分たちがこのシステムを守るんだ」という責任感が生まれます。
いつ相談すべきか?ロードマップで解説
実務的な正解は、運用テスト(ユーザー受け入れテスト)が始まる2〜3ヶ月前です。
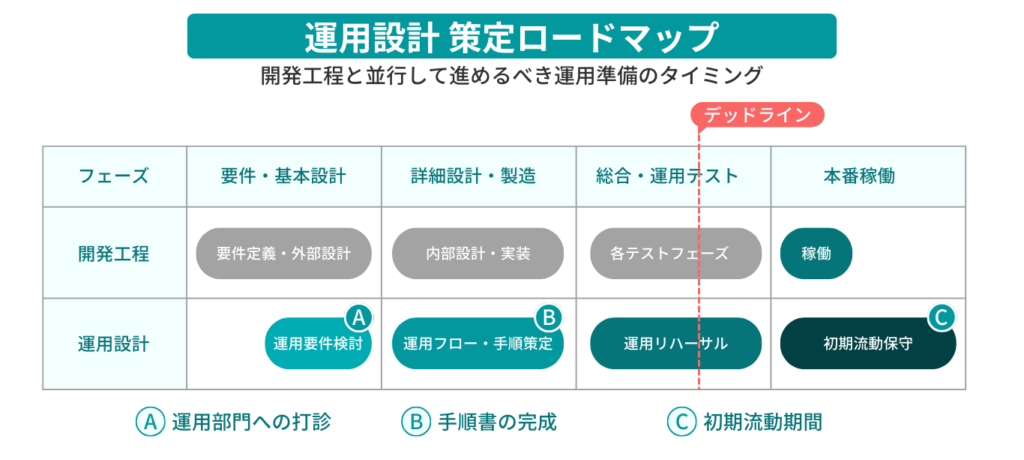
| 開発フェーズ | 運用設計のアクション | 目的・状態 |
|---|---|---|
| 基本設計・詳細設計 | 【A】運用部門への打診 | 基本設計後半からキーマンを巻き込み、現場の制約事項を確認する。運用要件の検討を開始。 |
| 結合・運用テスト | 【B】手順書の完成 (デッドライン) | 運用テスト開始時までにドラフトを完成させ、テスト内で手順の妥当性を検証する。 |
| 本番稼働直後 | 【C】初期流動保守 | 稼働後1〜2ヶ月は開発メンバーがバックアップし、FAQを充実させる。 |
要注意: 開発の遅延が運用準備を圧迫しがちです。運用テストで「ルールの検証」ができないまま本番を迎えることが、パニックの最大要因となります。
運用設計のデッドラインは「テスト中盤」である3つの理由
- 運用テストは「ルールの検証」の場だから
運用テストの目的は、単にシステムが動くかを見ることではありません。設計した運用ルール(手順書や連絡網)通りに、現場が混乱なく回るかを検証することです。 - オペレーターの習熟期間が必要だから
マニュアルが完成してから、実際にそれを見て操作する運用担当者やヘルプデスクが慣れるまでには時間がかかります。テスト期間中に使い倒してもらうことで、事故を防ぎます。 - 未知の不具合はテスト中に必ず出るから
テスト期間中に実際に模擬障害を行うと、「連絡網の番号が古い」「夜間の承認ルートが現実的でない」といった課題が必ず出ます。これを微調整できるのがこの時期なのです。
まとめ:運用設計は開発チームから運用への「最高のバトン」
システム運用設計は、単なる事務的な手続きではありません。開発チームが作り上げたシステムを、予期せぬトラブルや品質劣化から守り、現場で長く使われ続けるための守りの要です。
- 初動を固める:インシデント管理と連絡網でパニックを防ぐ。
- 継続を守る:定期監視と変更管理でシステムの劣化を防ぐ。
- 運用部門と対話する:現場の現実を設計に反映し、円滑なバトンタッチを行う。
この土台がしっかりしていれば、リリース後のPMの仕事は火消しから次なる改善への提案へと変わります。
運用設計を整えて無事に稼働を迎えても、SIerやベンダーの立場では、システムが本当に現場に定着して成長していく過程を最後まで見届けることは困難です。
「作って終わりではなく、ユーザーの反応を見ながらシステムを育てていきたい」と少しでも感じているなら、あなたの運用知識がそのまま活きる「社内SE」へのキャリアチェンジを考えてみませんか?【PM・リーダー向け】UATでデグレ連発は撤退のサイン?炎上現場を生き抜いたあなたが社内SEで無双できる理由
コピペで使える!システム運用準備チェックリスト
最後に、現場ですぐに使えるチェックリストをご用意しました。テキストをコピーして、プロジェクト管理ツール等に貼り付けてご活用ください。
- [ ] ユーザーからの問い合わせ窓口(ヘルプデスク等)は一本化されているか?
- [ ] 障害の重要度(S/A/B/Cなど)の定義はステークホルダー間で合意できているか?
- [ ] 休日・夜間の緊急連絡先リスト(エスカレーションパス)は最新か?
- [ ] 運用部門(または保守担当)と運用フローの合意は取れているか?
- [ ] プログラムの本番反映(デプロイ)やパッチ適用の承認フローは確立しているか?
- [ ] バッチ処理やバックアップ、死活監視の主担当者(一次対応者)が明記されているか?
- [ ] 障害や操作のログを「誰が・いつまで・どのような形」で保管するか決まっているか?
- [ ] 万が一のデータ消失時に備えたリストア(復旧)手順は、実際に検証済みか?





















